

We know that, Python is a general purpose object oriented programming language used in large scale complex projects. However, Python is also a popular choice as a scripting language. If you have ever used shell scripts in UNIX or batch files in Windows, you know how powerful they are in automating tasks. Only thing they lacs is the capability of a full featured programming language. How powerful do you think it would be if we could combine the power of scripting with the capability of a fully functional programming language with support for object oriented programming. Well, Python can help here. In this post I will demonstrate how basic directory and file handling operations can be automated through Python. I will explain the concepts through a case study so that you can get an understanding of the potential usage scenarios and apply the same in your project if required.
Before going to the coding examples, let me explain what we are going to achieve in this mini project. Every project needs to maintain some kind of document repository in a local hard drive or network drive to store the software requirement specifications, design documents, testing reports, development status reports etc. Normally those documents get updated regularly by different persons working on the project may be for correction, review or incorporating new change requests.
When a new document version is created, we normally increment the version number so that we can identify the latest one while maintaining the history of past modifications. As the number of documents in the folder keep on increasing over time, we need to archive the older versions to keep the folder clean. In addition to that a report containing the latest document version numbers, last modified time and modified by user can really be helpful for a project manager. Let’s explore how we can do this in Python. First, break down the project tasks in small logical groups.
Step 1: Define the folder structure of the project
Step 2: Identify the last modified file for each unique document in a folder and subfolders
Step 3: Move all older file versions to the Archive folder except for the last modified one
Step 4: Generate a report specifying each document, latest version number, last modified date and user who modified the file
Now let’s deep dive into implementation detail for each step.
Step 1: Define the folder structure for the project
For the purpose of our mini project, I have taken a simplified folder structure as you can see in the image below. In a real world project the structure will be much complex with lots of documents. But, the concept that we learn here will still apply.

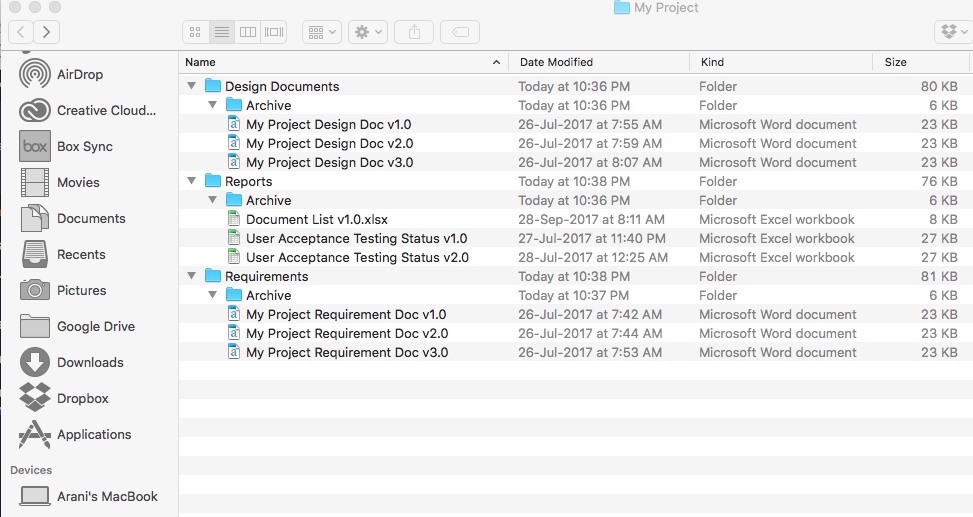
As you can see from the naming convention of the documents, each document name ends with vN.N pattern. The number followed by ‘v’ is the version number. Length of version number can vary, e.g. 2.0, 1.4.31, 5.3.4.2 are all valid version number patterns.
The code that I am going to show you is written in Python 3 and following module imports are used in this python code:
import openpyxl import os import re import shutil import time from time import strftime
Step 2: Identify the last modified file for each unique document in a folder
To identify the latest version of each file, I have used two functions. The first function populate_file_object(file) takes a filename as input and returns a fully populated FileInfo object we have defined. The FileInfo object holds attributes related to the file that will help us in simplifying our program. The second function uses the first function to simplify it’s work. Let us see the FileInfo object structure below:
# Define a Class to store file related attributes
class FileInfo:
def __init__(self):
self.full_name = None
self.base_name = None
self.last_mod_time = 0
self.file_version = None
self.extn = None
self.user_id = None
def __str__(self):
return 'Full Name: ' + self.full_name + '\n' + 'Extn: ' + self.extn + '\n' \
+ 'Version Number:' + self.file_version + '\n' + 'Base Name: ' + self.base_name + '\n' \
+ 'Last Modified Time: ' + strftime("%d %b %Y", time.gmtime(self.last_mod_time)) + '\n' \
+ 'Modified By: ' + str(self.user_id)
Let us find below what each attribute of the FileInfo object holds:
full_name – this is the full name of the file including file extension and version number (e.g. My Project Design Doc v3.0.docx)
base_name – this is the substring of the file name excluding file extension and version number (e.g. My Project Design Doc)
last_mod_time – this is the time when the file was last modified
file_version – this is the substring of the filename that contains the version number (e.g. v3.0)
extn – this is the file extension (e.g. .docx for word documents)
user_id – this is the name of the user who last modified the file
The __str__(self) function returns a user readable string representation of the FileInfo object. If we pass a FileInfo object to the print() function of python, python interpreter will automatically invoke this function.
Now let us see how we can get a FileInfo object for any file name:
#Define method to extract attributes from full file name
def populate_file_object(file):
file_obj = FileInfo()
#Set file name
file_obj.full_name = file
#Set extension
file_extn = file.split('.')[len(file.split('.')) - 1]
file_obj.extn = file_extn
#Set version number
version_number = None
taskMatches = re.search(r'[v](\d[.])+', file, re.I)
if taskMatches:
version_number = taskMatches.group()
if version_number:
file_obj.file_version = version_number[:len(version_number)-1]
#Set base name
file_name_without_extn = file[:file.find(file_extn) - 1]
file_name_without_version = None
if version_number:
file_name_without_version = file_name_without_extn[:file.find(version_number) - 1]
file_obj.base_name = file_name_without_version
#Set Modified time
mod_time = os.path.getmtime(file)
file_obj.last_mod_time = mod_time
#Set user Id
file_info = os.stat(file)
try:
import pwd #Only available in UNIX based platforms
userinfo = pwd.getpwuid(file_info.st_uid)
except (ImportError, KeyError):
print("Could not get the owner name for", file)
else:
print("file owned by:", userinfo[0])
file_obj.user_id = userinfo[0]
return file_obj
Let me explain how I have populated the required fields in a FileInfo object.
- First we have set the full_name attribute to the input we are getting.
- Next file extension is derived. Here I have used the split() method of the string object. Full file name is split in place of dots(‘.’). As every file extension ends with .xyz format, we have split the full input string by dots and then taken the last occurrence of ‘dot’ as the filename contains other dots as well in version number. The split() function returns an array of strings splitted by ‘.’. So we have calculated the length of the array by using the len() function and then taken the string stored in the last index of the array.
- In the next step we have derived the version number of the document. Now, this is a bit tricky because version number can start with small or capital ‘V’ and may contain one or more sequence of ‘.n’s (e.g. v1.0 or V10.3.5.2 etc). Therefore, to simplify our task we have used regular expressions. We have used inbuilt ‘re’ package of python to accomplish this. We have used re.search() function with regular expression ‘r'[v](\d[.])+’’. We have used case insensitive search by passing ‘re.I’ parameter to re.search() method. Regular expression is a very powerful tool for text searches by patterns. Without regular expressions we have to write a lengthy code to achieve the same. In this regular expression, we have used [v] to search for ‘v’ or ‘V’ and then ‘(\d[.])+’ to specify one or more occurrences of a digit followed by ‘.’. To learn more about regular expressions you can refer to python documentation for regular expressions (https://docs.python.org/3/library/re.html?highlight=re#module-re).
- In the next step we have extracted the base name information which the actual document name without the extension and the version number. This is quite straight forward as we already know the file extension and version number. So, we have to find the index in the full filename string where the version number starts and just take the substring from the beginning to the index – 1 position.
- Next we have extracted when the file was last modified by using os.path.getmtime() function. This function returns the time in seconds since the epoh (see time module for details). We have to use other formatting functions (e.g. strftime(“%d %b %Y”, time.gmtime(self.last_mod_time)) is used in __str__(self) function in FileInfo class) to get a easily readable format of the time.
- In the last few lines we have extracted the user name who has updated the file. For that we have used os.stat() function and pwd module. os.stat() module returns attributes related to a file. However the user id returned by ST_UID attribute of stat object provides a numerical representation of the user id. Therefore, we have used pwd module to get the actual user name. However, please note that this module is available only in UNIX based systems. Therefore, we have wrapped the code section in try block to handle the exception.
No that we have a function to give us every detail we need about a file let us see how we can use that information to identify the latest file versions. We will user find_latest_files() function to achieve this. Please go through the code below:
#Define method to find latest file version for each document and add that to the dictionary
def find_latest_files(folder,file_mod_time_dict):
os.chdir(folder)
for file in os.listdir():
if os.path.isfile(file):
file_obj = populate_file_object(file)
if file_obj.base_name:
if file_obj.base_name in file_mod_time_dict:
if file_obj.last_mod_time > file_mod_time_dict[file_obj.base_name].last_mod_time:
file_mod_time_dict[file_obj.base_name] = populate_file_object(file)
else:
file_mod_time_dict[file_obj.base_name] = populate_file_object(file)
else:
os.chdir(file)
find_latest_files(str(os.getcwd()),file_mod_time_dict)
os.chdir('../')
In the code snippet specified above, I have defined a function to identify latest file version for each document. The function takes two inputs or arguments. The first argument is the root folder path of our project and the second one is a python dictionary (dict) object that will eventually hold the latest file version for each document. The function traverses through all the subfolders, scans all documents present in the folders and populates the dictionary with last modified file for each document. The ‘key’ of the dictionary is the ‘base name’ of the document and the value is a ‘FileInfo’ object which refers to the last modified version of the document. Now let us check each step in detail.
- To begin with, I have used the os.chdir() function from os module to change the current directory to the root folder of our project (passed as the first argument to this function).
- Once we are in the root directory, we need to iterate through each file and directory within the root directory to find the latest document versions. For that, I have looped through all the files and directories within the root directory.
- Now, if we find a file, we need to add this to the dictionary or updated the dictionary entry if an older version of the document already exists in the dictionary. For this, we have invoked populate_file_object() function specified above to get all attributes related to the file. After that we have checked whether the document base name is present in the ‘file_mod_time_dict’ dictionary. If the entry is present then we have retrieved the FileInfo object from the dictionary entry and compared the last modified time attribute with the current file we are working on. If the last modified time is after the last modified time of the existing entry in the dictionary then the dictionary entry is updated to hold the latest entry. This way our dictionary will only contain the last modified entry of each document once we have iterated through all the files.
- Next we have to decide what to do if we encounter a sub directory while looping through the files. For any sub directory, we have to repeat the whole process I have described through steps 1 to 3. We have to continue doing that until there is no subdirectory present within a directory. To achieve this, we have made the function find_latest_files() a recursive function. A recursive function is a function which calls itself from the function body. In this function, we have recursively called the same function if we encounter a directory by passing the directory name as the first argument.
- After calling the the function, we have used os.chdir(‘../’) method to go back to the parent directory and continue execution.
So, find_latest_files() function will iterate through all the folders and subfolders present under the project root directory and will populate file_mod_time_dict dictionary object with all document base names as keys and corresponding FileInfo objects as values. As this article is a bit lengthy, I have split it into two parts. Our first part end here. In the second part of the article you will learn about how steps 3 and 4 used to actually archive old files and generate the valuable report.



